1. Teori pada ilmu komputer yang menjelaskan tingkat efisiensi suatu model matematis dalam menyelesaikan suatu masalah disebut
A. Teori Perhitungan
B. Teori Kalkulasi
C. Teori Komputasi
D. Teori Komputer
2. Teori ini dibagi menjadi tiga cabang utama, yaitu kecuali
A. Teori komputabilitas
B. Teori komputer
C. Teori kompleksitas
D. Teori bahasa dan otomata
3. Teori yang membahas beberapa mesin abstrak dan masalah yang dapat diselesaikan oleh mesin tersebut disebut
A. Teori komputabilitas
B. Teori komputer
C. Teori kompleksitas
D. Teori bahasa dan otomata
4. Berikut adalah beberapa jenis mesin abstrak, kecuali
A. Mesin Turing
B. Automata Hingga
C. Automata Tak Hingga
D. Push Down Automata
5. Aspek waktu dan ruang termasuk ke dalam teori
A. Komputabilitas
B. Komputer
C. Kompleksitas
D. Bahasa dan otomata
6. Framework atau model pemrograman yang terdiri atas fungsi Map dan fungsi Reduce disebut
A. MapReduce
B. Hadoop
C. Spark
D. Tidak ada jawaban yang benar
7. Fungsi map adalah
A. Fungsi untuk menggabungkan data
B. Fungsi untuk mengurangi data
C. Fungsi untuk memetakan suatu operasi ke sebuah list
D. Semua jawaban benar
8. Fungsi reduce adalah
A. Fungsi untuk menggabungkan data
B. Fungsi untuk mengurangi data
C. Fungsi untuk memetakan suatu operasi ke sebuah list
D. Semua jawaban benar
9. Fungsi MapReduce dikembangkan oleh
A. Microsoft
B. Google
C. Facebook
D. IBM
10. MapReduce umum digunakan pada
A. Big data
B. Small data
C. Medium data
D. Large data
11. Pemrosesan paralel adalah
A. Pemrosesan yang dilakukan secara berurutan satu persatu hingga akhir
B. Pemrosesan yang dilakukan secara acak
C. Pemrosesan yang membagi proses menjadi beberapa bagian dan tiap bagian dilakukan secara bersamaan
D. Semua salah
12. Arsitektur komputer yang memiliki satu jalur data dan satu jalur instruksi disebut
A. SIMD
B. SISD
C. MIMD
D. MISD
13. Pada arsitektur SIMD, jumlah jalur instruksi yang ada adalah
A. 6
B. 7
C. 1
D. 10
14. Pada arsitektur SIMD, jumlah jalur data yang ada adalah
A. 6
B. 7
C. 10
D. Semua benar
15. CPU dengan banyak inti termasuk dalam arsitektur
A. SIMD
B. SISD
C. MIMD
D. MISD
Jawaban:
1. C
2. B
3. D
4. C
5. C
6. A
7. C
8. A
9. B
10. A
11. C
12. B
13. C
14. D
15. C
Thursday, 12 July 2018
Saturday, 16 June 2018
Parallel Processing: Teknik Mempercepat Pemrosesan pada Komputer
Setelah sebelumnya saya bahas tentang MapReduce, kali ini saya mau bahas ide di balik MapReduce, yaitu pemrosesan paralel. Umumnya, komputer memproses sesuatu secara seri, sekuensial atau berurutan. Jadi alurnya lurus terus dari awal hingga akhir proses. Walaupun ada perulangan atau percabangan, proses tersebut tetap dilakukan secara sekuensial. Kemudian, muncul sebuah masalah saat memproses sesuatu yang jumlahnya besar dan banyak, misalnya mengurutkan suatu data yang jumlahnya 10.000 record. Jika data tersebut diurutkan secara sekuensial dengan membandingkan tiap-tiap record (menggunakan Bubble Sort atau Selection Sort), komputer membutuhkan waktu yang sangat lama hingga seluruh data terurut.
Kemudian dikembangkanlah pendekatan baru agar masalah ini dapat diselesaikan lebih cepat. Pendekatan tersebut diberi nama Divide and Conquer. Pendekatan ini membagi sebuah masalah menjadi lebih kecil, kemudian masalah kecil tersebut diselesaikan dan hasilnya digabung kembali. Ini menjadi permulaan pemrosesan paralel. Pada pemrosesan paralel, tiap-tiap proses dikerjakan secara bersamaan atau hampir bersamaan sehingga proses tersebut dapat selesai lebih cepat. Jadi, masalah mengurutkan data dengan 10.000 record akan selesai lebih cepat dengan menggunakan pemrosesan paralel dibanding sekuensial. Ini seperti suatu pekerjaan dikerjakan oleh lebih dari 1 orang.
Perkembangan pemrosesan paralel didukung oleh perkembangan arsitektur komputer. Menurut Michael J. Flynn, arsitektur komputer itu dibagi menjadi 4 jenis, yakni:
- Single Instruction stream, Single Data stream (SISD)
- Single Instruction stream, Multiple Data stream (SIMD)
- Multiple Instruction stream, Single Data stream (MISD)
- Multiple Instruction stream, Multiple Data stream (MIMD)
Pada arsitektur SISD, komputer hanya memiliki satu buat prosessing unit (PU) yang mengakses satu jalur data. Komputer dengan arsitektur seperti ini sulit untuk melakukan pemrosesan paralel. Contoh sederhana dari komputer dengan arsitektur ini adalah PC sebelum tahun 2000 dengan single core prosessor.
 |
| Diagram Arsitektur SISD. Source: wikipedia.org |
Arsitektur SIMD sedikit berbeda dari SISD. Pada SIMD, sebuah processing unit terhubung dengan beberapa jalur data. Ini membuat satu instruksi dapat melakukan hal yang sama dengan data yang berbeda secara simultan. SIMD sudah dapat melakukan pemrosesan paralel.
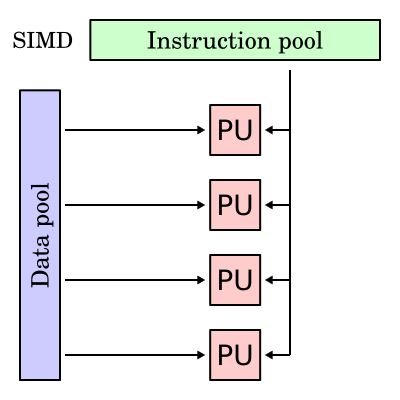 |
| Diagram Arsitektur SIMD. Source: wikipedia.org |
Arsitektur MISD mungkin arsitektur yang jarang kita lihat karena jarang sekali komputer yang dapat melakukan beberapa instruksi pada satu jalur data. Maksudnya adalah terdapat beberapa operasi yang berbeda (misal: penjumlahan dan perkalian matriks) yang dilakukan pada data yang sama (misal: dua buah matriks dilakukan operasi penjumlahan dan perkalian secara bersamaan). Salah satu contoh komputer dengan arsitektur MISD adalah komputer pengendali pesawat luar angkasa.
 |
| Diagram Arsitektur MISD. Source: wikipedia.org |
Arsitektur terakhir yaitu MIMD. MIMD adalah arsitektur kedua yang sering ditemui setelah SIMD. Komputer dengan arsitektur ini memiliki beberapa prosessing unit yang bekerja pada beberapa jalur data. Komputer dengan MIMD umum digunakan untuk simulasi, modeling, CAD dan CAM. Komputer-komputer ini dapat dibagi menjadi shared-memory atau distributed memory. Pembagian ini berdasarkan bagaimana komputer mengakses memori. Pada shared-memory, komputer hanya terhubung pada sebuah memori yang secara global dapat diakses oleh seluruh processing unit yang ada. Pada distributed memory, tiap processing unit memiliki memorinya sendiri dan secara langsung tidak dapat mengetahui isi dari memori pada processing unit yang lain.
 |
| Diagram Arsitektur MIMD. Source: wikipedia.org |
Kita coba bahas lagi contoh yang tadi, mengurutkan data yang memiliki 10.000 record. Data tersebut kita urutkan menggunakan algoritma merge sort. Algoritma ini akan membagi data menjadi beberapa bagian kemudian tiap bagian akan diurutkan dan selanjutnya digabungkan kembali.
Misal: 10.000 record dipecah menjadi n bagian sesuai dengan banyaknya processing unit. Tiap-tiap processing unit ini akan mengurutkan bagian record yang sudah diberikan secara bersamaan. Operasi pengurutan dilakukan secara sekuensial pada masing-masing processing unit. Setelah operasi pengurutan selesai, masing-masing processor akan melakukan operasi merge untuk menggabungkan bagian record yang telah terurut.
Tuesday, 17 April 2018
MapReduce: Cara Sederhana untuk Memroses Data Besar
Internet merupakan pusat informasi yang besar. Tiap saat orang-orang mengirimkan fotonya ke Instagram, mengirimkan curhatan mereka ke Twitter, dan mencari referensi untuk makan malam di Google. Data yang mereka proses banyak sekali. Membutuhkan waktu yang lama dan ruang yang besar agar dapat memproses data dengan jumlah besar.
Muncullah ide dari engineer Google untuk mempercepat proses tersebut dan megurangi beban penyimpanan. Mereka menamai metode tersebut MapReduce. MapReduce adalah framework atau model pemrograman yang terdiri atas dua fungsi, yaitu fungs untuk memproses data key/value pair dan fungsi untuk menggabungkan hasilnya menjadi satu.
Ide ini terinspirasi dari fungsi map dan reduce milik Lisp dan beberapa bahasa pemrograman fungsional lainnya. Fungsi map bertugas untuk menerapkan suatu operasi terhadap seluruh elemen pada array dan fungsi reduce bertugas untuk mereduksi suatu data jika data tersebut memiliki key yang sama.
Secara umum, proses yang terjadi pada MapReduce adalah sebagai berikut:
- Program menerima input dalam bentuk key/value pairs
- Kemudian, fungsi map menyebar input tersebut ke tiap processor untuk diolah sehingga tiap processor menghasilkan data key/value pairs yang baru.
- Selanjutnya, hasil data key/value pair dari tiap processor diterima oleh fungsi reduce untuk dicek dan menggabungkan data dengan key yang sama.
Pseudo-code penggunaan MapReduce pada kasus untuk menghitung frekuensi kemunculan suatu kata pada dokumen besar adalah seperti berikut:
map(String key, String value):
//key: document name
//value: document content
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
//key: a word
//values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Dari pseudo-code di atas, fungsi map akan menuliskan kata yang ditemuinya dan menghitung kemunculannya (pada contoh di atas hanya “1”). Kemudian fungsi reduce akan menjumlahkan semua kemunculannya dari tiap kata.
Beberapa contoh penggunaan MapReduce lainnya adalah distributed grep dan menghitung frekuensi akses suatu URL.
Untuk saat ini, MapReduce sudah tidak digunakan oleh Google. Kita bisa lihat implementasinya pada Hadoop, project open source milik Apache yang khusus menangani Big Data.
MapReduce milik Hadoop sedikit berbeda dari Google. MapReduce miliki Hadoop mendukung fungsi partitioning untuk mempartisi data yang diolah. Kemudian juga mendukung fungsi combiner untuk menggabungkan data dengan key yang sama di area lokal (penggabungan dilakukan oleh masing-masing processor).
Thursday, 5 April 2018
Pengenalan Teori Komputasi dan Implementasinya
Teori komputasi adalah sebuah teori pada ilmu komputer yang menjelaskan tingkat efisiensi suatu model matematis dalam menyelesaikan suatu masalah. Teori ini dibagi menjadi tiga cabang utama, yaitu:
- Teori bahasa dan otomata
- Teori komputabilitas
- Teori kompleksitas
Teori bahasa dan otomata membahas beberapa mesin abstrak dan masalah yang dapat diselesaikan oleh mesin tersebut. Mesin ini akan menerima sebuah input dan secara otomatis memproses input tersebut. Mesin inilah yang disebut otomata. Otomata sangat dekat dengan teori bahasa formal, karena dengan otomata, sebuah bahasa dapat dibangun.
Lalu, teori komputabilitas membahas sejauh mana sebuah masalah dapat diselesaikan dengan komputer dan teori kompleksitas membahas seberapa efisien suatu masalah diselesaikan.
Dalam implementasinya, ketiga teori ini saling berkaitan. Pertama, seorang ilmuan komputer akan menggunakan model abstrak matematis untuk menyelesaikan masalah yang ada. Umumnya model yang digunakan adalah Turing machine, karena Turing machine mudah untuk dibentuk, dapat dianalisa dan digunakan untuk membuktikan hasil yang didapat, serta dianggap sebagai model yang hebat.
Selanjutnya, ilmuan komputer mulai melakukan proses pemecahan masalah menggunakan model abstrak tersebut berdasarkan teori komputabilitas. Salah satu contoh kasusnya adalah masalah halting. Halting merupakan kondisi di mana sebuah program dengan suatu input harus berhenti atau berjalan selamanya. Masalah ini mudah untuk dianalisa dan tidak dapat dipecahkan dengan Turing machine.
Terakhir, ilmuan komputer akan menghitung seberapa efisien masalah tersebut diselesaikan. Aspek yang diperhatikan adalah, waktu dan ruang. Aspek waktu menunjukan berapa lama masalah tersebut diselesaikan. Aspek ruang menunjukan berapa besar tempat yang digunakan untuk memecahkan masalah tersebut.
Untuk menghitung kedua aspek tersebut, ilmuan komputer menuliskan solusi yang didapat menjadi sebuah fungsi dengan besar input dari suatu masalah. Sebagai contoh, pencarian suatu nilai di dalam larik membutuhkan waktu yang besar jika larik tersebut besar juga. Untuk memudahkan masalah tersebut, notasi Big O digunakan.
Dalam implementasinya, ketiga teori ini saling berkaitan. Pertama, seorang ilmuan komputer akan menggunakan model abstrak matematis untuk menyelesaikan masalah yang ada. Umumnya model yang digunakan adalah Turing machine, karena Turing machine mudah untuk dibentuk, dapat dianalisa dan digunakan untuk membuktikan hasil yang didapat, serta dianggap sebagai model yang hebat.
Selanjutnya, ilmuan komputer mulai melakukan proses pemecahan masalah menggunakan model abstrak tersebut berdasarkan teori komputabilitas. Salah satu contoh kasusnya adalah masalah halting. Halting merupakan kondisi di mana sebuah program dengan suatu input harus berhenti atau berjalan selamanya. Masalah ini mudah untuk dianalisa dan tidak dapat dipecahkan dengan Turing machine.
Terakhir, ilmuan komputer akan menghitung seberapa efisien masalah tersebut diselesaikan. Aspek yang diperhatikan adalah, waktu dan ruang. Aspek waktu menunjukan berapa lama masalah tersebut diselesaikan. Aspek ruang menunjukan berapa besar tempat yang digunakan untuk memecahkan masalah tersebut.
Untuk menghitung kedua aspek tersebut, ilmuan komputer menuliskan solusi yang didapat menjadi sebuah fungsi dengan besar input dari suatu masalah. Sebagai contoh, pencarian suatu nilai di dalam larik membutuhkan waktu yang besar jika larik tersebut besar juga. Untuk memudahkan masalah tersebut, notasi Big O digunakan.
Kemudian, masalah seperti apa yang dapat diselesaikan? Pada bidang matematika, teori komputasi umum digunakan untuk permasalahan analisis numerik. Beberapa masalahnya adalah,
- Pencarian akar suatu fungsi, seperti metode bisection, metode Newton, serta metode Secant
- Interpolasi yaitu untuk mendapatkan data point baru dari beberapa data point yang sudah diketahui
- Operasi pada matriks, seperti dot product, cross product
- Aljabar linier.
Pada masalah pencarian akar suatu fungsi, metode yang digunakan dapat berupa metode iteratif menggunakan iterasi khusus. Iterasi tidak dilakukan pada fungsi yang diberikan, tetapi dilakukan pada fungsi tambahan dan mengaproksimasi nilai akar menggunakan fungsi tersebut. Sehingga proses iterasi tidak memakan waktu yang lama. Metode yang menggunakan iterasi adalah metode Newton dan metode Secant.
Tak hanya menggunakan iterasi, pencarian akar pun dapat dilakukan dengan membagi fungsi menjadi beberapa bagian. Ini dilakukan agar ruang yang digunakan tidak besar. Metode yang menggunakan proses ini adalah bisection dan regula falsi.
Sunday, 21 January 2018

Subscribe to:
Posts (Atom)